はじめに
2018年9月、RDS Auroraクラスターの停止、開始機能がリリースされました。
・Amazon Aurora がデータベースクラスタの停止、開始へのサポートを開始
https://aws.amazon.com/jp/about-aws/whats-new/2018/09/amazon-aurora-stop-and-start/
※この停止機能は、クラスターの機能ですので、Auroraクラスターに複数のリードレプリカが存在する場合、マスターとリードレプリカがすべて停止します。2018年12月時点では、マスターや特定のリードレプリカのみを停止することはできないようです。
それまでは、Aurora以外のDBエンジンのRDSについては停止が可能でしたが、このリリースにより、Auroraも停止可能となりました。
開発環境などでは、使用しない間は、一時的に停止することでコスト削減ができます。
ここでは、Lambda関数を使用して、自動的に、平日営業時間帯のみ起動し、夜間・休日は停止するよう設定する方法を記載します。
Lambda関数を使用したAuroraクラスターの自動停止方法については、すでに他の方が公開されています。
・lambdaでAuroraを停止する – Qiita
https://qiita.com/blux2/items/af9bcc5081d8b6659e4f
しかし、LambdaでPython 3を使用する場合は、Lambda環境のSDK for Python (boto3) が古くて、そのままではAuroraクラスターの停止・起動が実行できないため、最新のboto3パッケージとLambda関数を含めたうえでzipファイルを生成し、Lambdaにデプロイする必要がありました。
その方法で、やりたいことは実現できるのですが、AWSマネジメントコンソールでソースコードを確認、編集できず、デプロイ→テスト→直し→再デプロイ→テストといったフローで少し使い勝手がよくありません。
(ふだんからAWSマネジメントコンソールをあまり使わず、AWSCLIで操作している方ならそれでもよいのでしょうが。)
そんなとき、2018年11月末に、Lambda Layersという機能がリリースされました。
・新機能 AWS Lambda :あらゆるプログラム言語への対応と一般的なコンポーネントの共有 – Amazon Web Services ブログ
https://aws.amazon.com/jp/blogs/news/new-for-aws-lambda-use-any-programming-language-and-share-common-components/
この機能により、今回のように最新のSDKや、複数のLambda関数で使用する共有ロジックを「レイヤー」として外出しして配置し、本来の目的のみLambda関数で実装することができるようになりました。
今回は、最新のboto3パッケージをレイヤーとして設定し、Auroraクラスターを自動停止・起動するロジックのみをLambda関数として作成することにします。
また、自動停止・起動対象とするAuroraクラスターは、DBクラスター名を指定するのではなく、タグで判断するようにしてみました。
なお、boto3パッケージをレイヤーとして設置する方法は、次の記事を参考にしました。
・Lambda Layers で最新の AWS SDK を使用する – Qiita
https://qiita.com/hayao_k/items/b9750cc8fa69d0ce91b0
Lambda関数の仕様
- RDS Auroraクラスターを停止・起動する。
- 停止、起動にする関数はそれぞれ別に作成する(変数で工夫してひとつにまとめてもよいでしょう)。
- 対象となるRDS Auroraクラスターは、タグのキーが「AUTO_STARTSTOP」、値が「true」のものとする。
- Lambda関数のランタイムはPython 3.6
RDS Auroraクラスターの設定
自動停止・起動したい「DBクラスター」に対して、次のタグを設定します。
- キー: AUTO_STARTSTOP
- 値: true

DBインスタンスのタグではなく、DBクラスターのタグに設定するのがポイントです。
Lambdaの設定
次の設定を行います。
1. レイヤーの作成、設定
2. 実行ロール、ポリシー設定
3. Lambda関数の設定
4. 定期実行設定
5. 動作確認
1. レイヤーの作成、設定
最新のboto3パッケージを作成し、レイヤーとして設定します。
レイヤーの作成
適当なPCもしくはサーバー環境のディレクトリに、最新のboto3をインストールします。
※僕は手持ちのLinuxサーバーで実行しました。
$ mkdir python $ pip install -t ./python boto3 -- Installing collected packages: jmespath, docutils, six, python-dateutil, urllib3, botocore, futures, s3transfer, boto3 Successfully installed boto3-1.9.61 botocore-1.12.61 docutils-0.14 futures-3.2.0 jmespath-0.9.3 python-dateutil-2.7.5 s3transfer-0.1.13 six-1.11.0 urllib3-1.24.1 --
Lambdaのレイヤーとしてアップロードするため、zipファイルを生成します。
$ zip -r boto3-1.9.61.zip python $ ls -l boto3-1.9.61.zip -- -rw-r--r-- 1 inaba inaba 8009654 12月 7 15:24 boto3-1.9.61.zip --
Lambda Layersレイヤーの作成
AMSマネジメントコンソール Lambda で、レイヤーを作成します。
レイヤー設定で、「名前」にわかりやすくboto3のバージョンを含め、先ほど生成したレイヤーzipファイル「boto3-1.9.61.zip」をアップロードします。
- 名前: python-boto3-1-9-61
- 説明: boto3-1.9.61, botocore-1.12.61
- コードエントリタイプ: zipファイルをアップロード
- 互換性のあるランタイム: Python 2.7, Python 3.6, Python 3.7

2. 実行ロール、ポリシー設定
Lambda関数に付与するIAMロールのカスタムポリシーは以下のようにします。
CloudWatch Logsへの書き込みとRDS DBクラスターのリソース検索、参照、停止、起動権限を付与します。
※StartDBCluster, StopDBCluster権限の指定は、最近追加されました。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents",
"logs:GetLogEvents"
],
"Resource": [
"*"
]
},
{
"Effect": "Allow",
"Action": [
"rds:DescribeDBClusters",
"rds:ListTagsForResource",
"rds:StartDBCluster",
"rds:StopDBCluster"
],
"Resource": [
"*"
]
}
]
}
3. Lambda関数の設定
自動停止・起動したいRDS Auroraクラスターと同じリージョンでLambda関数を作成します。
ランタイムは、Python 3.6を指定します。
Auroraクラスターを停止するLambda関数
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Python 3.6
#
# 特定のタグを含むRDS Auroraクラスターを停止する。
#
# Lambda関数の環境変数で以下を設定する。
#
# ACCOUNTID: AWSのアカウントID
# TAGKEY: 対象とするAuroraクラスターに付与するタグキー文字列
# TAGVALUE: 対象とするAuroraクラスターに付与するタグ値(true)
#
# 対象とするインスタンスのタグで、
# Key: <TAGKEY>, Value: true
# を設定すること
#
import boto3
import time
import os
from botocore.client import ClientError
client = boto3.client('rds', os.environ['AWS_REGION'])
ACCOUNTID = os.environ['ACCOUNTID']
TAGKEY = os.environ['TAGKEY']
TAGVALUE = os.environ['TAGVALUE']
def lambda_handler(event, context):
stop_db_cluster()
def stop_db_cluster():
stop_dbs = []
# 全RDSインスタンスをリストアップ
all_dbs = client.describe_db_clusters()
for db in all_dbs['DBClusters']:
response = client.list_tags_for_resource(
ResourceName="arn:aws:rds:" + os.environ['AWS_REGION'] + ":" + ACCOUNTID + ":cluster:" + db['DBClusterIdentifier']
)
# タグによる絞り込み
for tag in response['TagList']:
if tag['Key'] == TAGKEY and tag['Value'] == TAGVALUE:
stop_dbs.append(db['DBClusterIdentifier'])
if stop_dbs:
targetlist = list(stop_dbs)
for dbname in targetlist:
print('Stop rds db cluster: %s' % (dbname))
response = _stop_db_cluster(dbname)
else:
print('Target rds db cluster is not exist.')
return
def _stop_db_cluster(db_cluster_identifier):
for i in range(1, 3):
try:
return client.stop_db_cluster(
DBClusterIdentifier=db_cluster_identifier
)
except ClientError as e:
print(str(e))
time.sleep(1)
raise Exception('Cannot stop rds db cluster: , ' + db_cluster_identifier)
# EOF
Auroraクラスターを起動するLambda関数
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Python 3.6
#
# 特定のタグを含むRDS Auroraクラスターを起動する。
#
# Lambda関数の環境変数で以下を設定する。
#
# ACCOUNTID: AWSのアカウントID
# TAGKEY: 対象とするAuroraクラスターに付与するタグキー文字列
# TAGVALUE: 対象とするAuroraクラスターに付与するタグ値(true)
#
# 対象とするインスタンスのタグで、
# Key: <TAGKEY>, Value: true
# を設定すること
#
import boto3
import time
import os
from botocore.client import ClientError
client = boto3.client('rds', os.environ['AWS_REGION'])
ACCOUNTID = os.environ['ACCOUNTID']
TAGKEY = os.environ['TAGKEY']
TAGVALUE = os.environ['TAGVALUE']
def lambda_handler(event, context):
start_db_cluster()
def start_db_cluster():
start_dbs = []
# 全RDSインスタンスをリストアップ
all_dbs = client.describe_db_clusters()
for db in all_dbs['DBClusters']:
response = client.list_tags_for_resource(
ResourceName="arn:aws:rds:" + os.environ['AWS_REGION'] + ":" + ACCOUNTID + ":cluster:" + db['DBClusterIdentifier']
)
# タグによる絞り込み
for tag in response['TagList']:
if tag['Key'] == TAGKEY and tag['Value'] == TAGVALUE:
start_dbs.append(db['DBClusterIdentifier'])
if start_dbs:
targetlist = list(start_dbs)
for dbname in targetlist:
print('Start rds db cluster: %s' % (dbname))
response = _start_db_cluster(dbname)
else:
print('Target rds db cluster is not exist.')
return
def _start_db_cluster(db_cluster_identifier):
for i in range(1, 3):
try:
return client.start_db_cluster(
DBClusterIdentifier=db_cluster_identifier
)
except ClientError as e:
print(str(e))
time.sleep(1)
raise Exception('Cannot start rds db cluster: , ' + db_cluster_identifier)
# EOF
使用レイヤーの設定
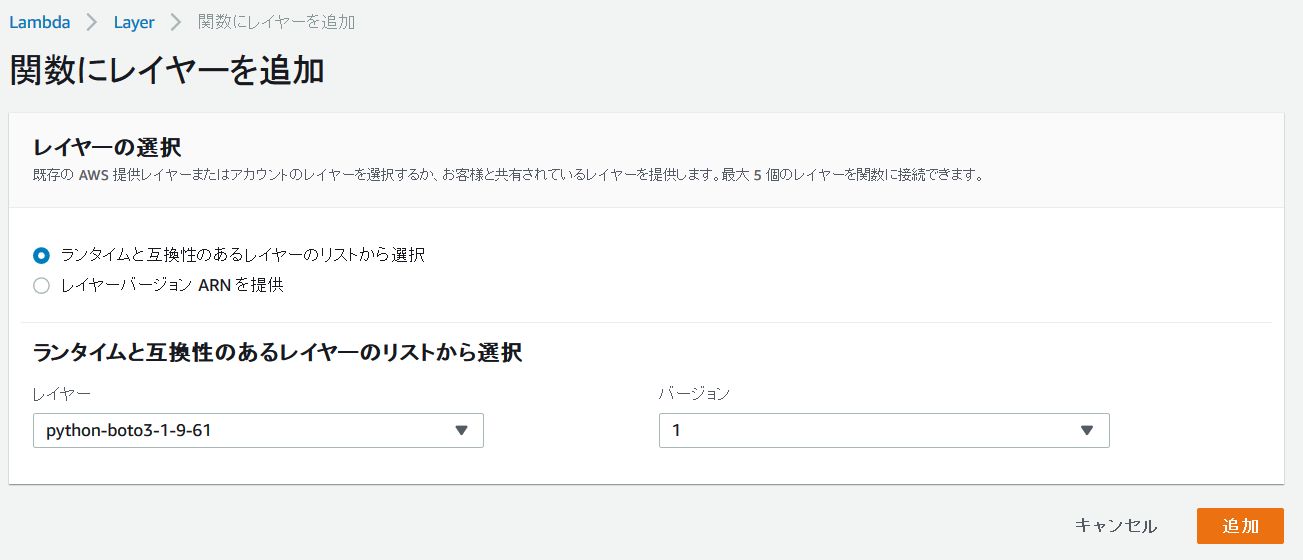
AWSマネジメントコンソール Lambda の、作成したLambda関数のDesigner画面で、「Layers」のアイコンをクリック。
「Layerの追加」ボタンをクリック。
レイヤーの選択で、先ほど追加したレイヤー「python-boto3-1-9-61」を指定します。
環境変数の設定
Lambda関数内で使用する、AWSアカウントIDと、対象とするRDS Auroraクラスターのタグを環境変数で指定します。
※AWSアカウントIDは、タグで対象リソースを絞り込む際に必要となります。
| キー | 値 |
| ACCOUNTID | <AWSアカウントID(12桁)> |
| TAGKEY | AUTO_STARTSTOP |
| TAGVALUE | true |

基本設定
メモリはデフォルトの128MBのままでOKです。
タイムアウトは、リトライをする場合はデフォルトの3秒では短かすぎてエラーすることがあるので、10秒や30秒などに変更します。
4. 定期実行設定
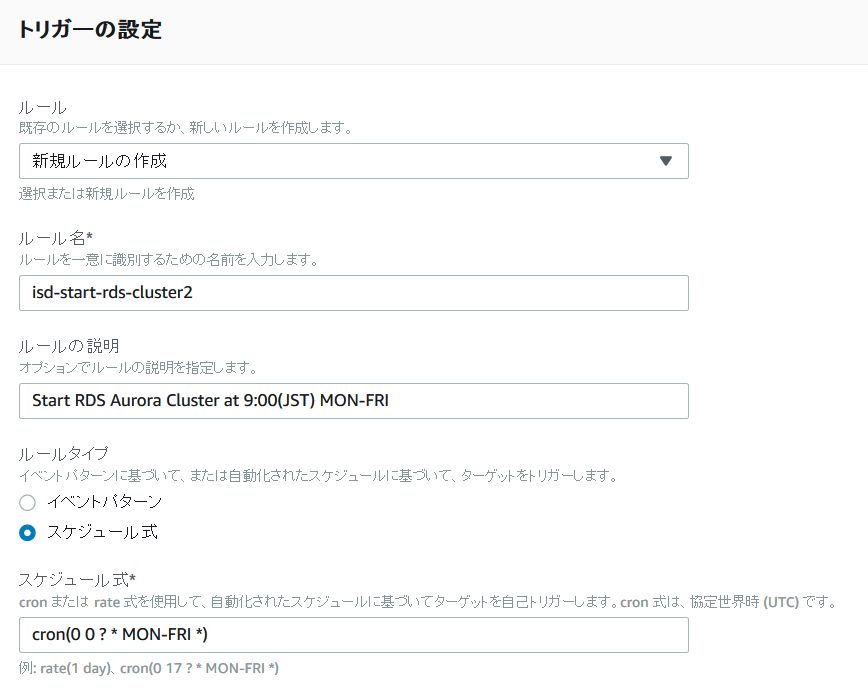
希望する曜日、時刻に停止・起動のLambda関数を実行するには、トリガーとしてCloudWatch Eventを指定して、スケジュールのルールを設定します。
以下は「日本時間の月-金の19時に自動停止」するスケジュール設定です。
「スケジュール式」の時刻はUTCで指定することに注意します。
cron(0 10 ? * MON-FRI *)

以下は「日本時間の月-金の9時に自動起動」するスケジュール設定です。
cron(0 0 ? * MON-FRI *)
5. 動作確認
設定が完了したら、Lambda関数をテストして、正しく動作することを確認します。
CloudWatch Logsのログも確認しましょう。
また、スケジュール設定で指定した日時に正しく停止・起動することも確認します
おわりに
AWS Lambda関数でRDS Auroraクラスターを自動停止、起動する方法を紹介しました。
最新のboto3パッケージを参照する部分は、Lambda Layersの機能を利用しました。
開発環境のコスト削減に、有効な設定だと思います。