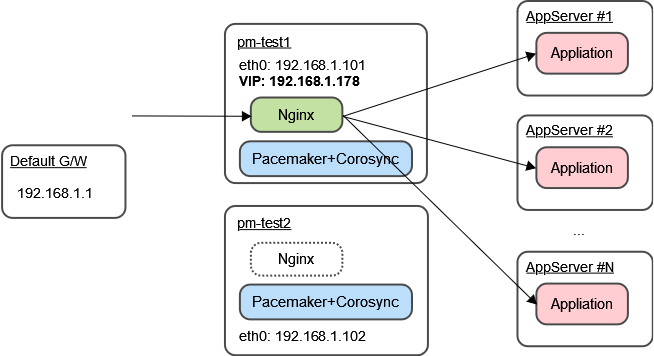
前編では、負荷分散用途の2台のNginxサーバーをPacemakerで冗長化する設定手順をまとめました。
後編では、とくに運用面の、Packmakerの動作、自動/手動フェイルオーバーなどについて記載します。
1. はじめに
2. サーバー構成
3. 設定手順
3.1. Nginxの設定
3.2. Pacemaker+Corosyncの設定
4. 今回の設定におけるPacemakerの動作(今回はここから)
5. 手動フェイルオーバー手順
6. 想定する障害と具体的なPacemakerの動作
7. おわりに
4. 今回の設定におけるPacemakerの動作
今回の設定におけるPacemakerの動作について、特に僕が気になった点をまとめておきます。
- Nginxの制御
Pacemakerの管理下にあります。
このため、スタンバイノードのNginxサービスは停止されています。
- Nginxの監視
Nginxの監視は、サービスプロセスの監視であり、HTTPのレスポンスやTCPポートの監視ではありません。
このためプロセスが生きていながら、何らかの原因でレスポンス応答がない場合には、フェイルオーバーは発生しないはずです(動作確認は行っていませんが。。)。
- フェイルオーバー時の動作
監視対象のリソースに何らかの障害が発生したとき、もしくは手動フェイルオーバーを実施したときは、もう1台のノードがアクティブとなります。
いわゆる「切り替わり」ですね。
フェイルオーバーしたサーバーでNginxが起動し、ネットワークインタフェースにVirtual IPアドレスが割り当てられます。
- 他ノードの監視
各ノードは、ネットワーク経由で相手のノードを監視しており、相手との通信が途絶えたとき、フェイルオーバーを実行し、自らがアクティブとなります。
- 優先順位と自動フェイルバック
今回の設定では2つのノードに対して優先順位をつけていません。
また、自動フェイルバックはしない設定(デフォルト)となっています。
ノードを2台とも停止したときなど、アクティブなノードが1つもない状態からノードを起動したときは、先にPacemakerを起動したノードがアクティブとなります。
また、自動フェイルオーバーが発生したあとの自動フェイルバック(元のノードへの自動切り戻し)は発生しません。
なお、Pacemakerに関連するログは、以下に出力されますので、より深く調査したいときや、意図した動作をしないときは、確認するとよいでしょう。
- pcsコマンドのログ: /var/log/pcsd/pcsd.log
- Corosyncクラスター制御ログ: /var/log/cluster/corosync.log
- Pacemakerリソース制御ログ: /var/log/pacemaker/pacemaker.log
5. 手動フェイルオーバー手順
手動フェイルオーバーにより、アクティブなノードを変更することができます。
手動フェイルオーバーを実施したいケースとしては、以下などが考えられます。
- フェイルオーバーを試したい
- サーバーを1台ずつメンテナンスしたい
- 自動フェイルオーバーした状態からフェイルバック(切り戻し)したい
手動フェイルオーバーするには、以下の3つの方法があります。
- pcs resource move コマンドでリソースを移動する
- pcs node standby コマンドでアクティブなノードをスタンバイ状態とする
- アクティブなノードでpacemakerサービスを停止する
「手動フェイルオーバー」という意味では、1または2が好ましいと思いますが、3は操作がシンプルかつ簡単です。
手動フェイルオーバーを実行する際は、事前に pcs status コマンドを実行し、出力結果の「Node List:」表示が、2ノードとも「Online」となっていることに注意します。
手動フェイルオーバー方法1. pcs resource move コマンドでリソースを移動する
まず、Pacemakerで、pm-test1 がアクティブになっていることを確認します。
(pm-test1)
# pcs status
Cluster name: cluster01
Status of pacemakerd: 'Pacemaker is running' (last updated 2023-04-12 15:51:17 +09:00)
Cluster Summary:
* Stack: corosync
* Current DC: pm-test1 (version 2.1.4-5.el8_7.2-dc6eb4362e) - partition with quorum
* Last updated: Wed Apr 12 12:51:17 2023
* Last change: Wed Apr 12 12:50:35 2023 by root via crm_resource on pm-test2
* 2 nodes configured
* 4 resource instances configured
Node List:
* Online: [ pm-test1 pm-test2 ]
Full List of Resources:
* Resource Group: rg01:
* rs-vip (ocf::heartbeat:IPaddr2): Started pm-test1
* rs-systemd-nginx (systemd:nginx): Started pm-test1
* Clone Set: rs-ping-gw-clone [rs-ping-gw]:
* Started: [ pm-test1 pm-test2 ]
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
pcsd: active/enabled
↑「Node List:」で、pm-test1, pm-test2 が2台とも Online となっています。
また、「Full List of Resources:」で、pm-test1 がアクティブとなっています。
pcs resource move コマンドで、リソースグループ rg01 を pm-test2 にフェイルオーバーします。
# pcs resource move rg01 pm-test2 Warning: A move constraint has been created and the resource 'rg01' may or may not move depending on other configuration
↑「A move constraint(制約)」が作成された、というWarningメッセージが出力されました。
数秒で、pm-test2 へのフェイルオーバーが完了します。
このとき、pm-test1 のNginxは停止しました。
# systemctl status nginx ● nginx.service - The nginx HTTP and reverse proxy server Loaded: loaded (/usr/lib/systemd/system/nginx.service; disabled; vendor pres> Active: inactive (dead) Apr 12 15:45:20 pm-test1 systemd[1]: Stopping The nginx HTTP and reverse proxy > Apr 12 15:45:20 pm-test1 systemd[1]: nginx.service: Succeeded. Apr 12 15:45:20 pm-test1 systemd[1]: Stopped The nginx HTTP and reverse proxy s> Apr 12 15:50:11 pm-test1 systemd[1]: Starting Cluster Controlled nginx... Apr 12 15:50:11 pm-test1 nginx[75851]: nginx: the configuration file /etc/nginx> Apr 12 15:50:11 pm-test1 nginx[75851]: nginx: configuration file /etc/nginx/ngi> Apr 12 15:50:11 pm-test1 systemd[1]: Started Cluster Controlled nginx. Apr 12 15:51:56 pm-test1 systemd[1]: Stopping The nginx HTTP and reverse proxy > Apr 12 15:51:56 pm-test1 systemd[1]: nginx.service: Succeeded. Apr 12 15:51:56 pm-test1 systemd[1]: Stopped The nginx HTTP and reverse proxy s
pm-test2 で操作してみます。
Pacemakerの状態を確認します。
(pm-test2)
# pcs status
Cluster name: cluster01
WARNINGS:
Following resources have been moved and their move constraints are still in place: 'rg01'
Run 'pcs constraint location' or 'pcs resource clear <resource id>' to view or remove the constraints, respectively
Status of pacemakerd: 'Pacemaker is running' (last updated 2023-04-12 15:53:59 +09:00)
Cluster Summary:
* Stack: corosync
* Current DC: pm-test1 (version 2.1.4-5.el8_7.2-dc6eb4362e) - partition with quorum
* Last updated: Wed Apr 12 15:53:59 2023
* Last change: Wed Apr 12 15:51:56 2023 by root via crm_resource on pm-test1
* 2 nodes configured
* 4 resource instances configured
Node List:
* Online: [ pm-test1 pm-test2 ]
Full List of Resources:
* Resource Group: rg01:
* rs-vip (ocf::heartbeat:IPaddr2): Started pm-test2
* rs-systemd-nginx (systemd:nginx): Started pm-test2
* Clone Set: rs-ping-gw-clone [rs-ping-gw]:
* Started: [ pm-test1 pm-test2 ]
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
pcsd: active/enabled
↑pm-test1 がスタンバイ(standby)、pm-test2 がアクティブとなっていることがわかります。
また、冒頭で「rg01の move constraints(制約)が存在している」というWarningメッセージが出力されています。
Nginxのサービスステータスを確認すると、Nginxが起動しています。
# systemctl status nginx
● nginx.service - Cluster Controlled nginx
Loaded: loaded (/usr/lib/systemd/system/nginx.service; disabled; vendor pres>
Drop-In: /run/systemd/system/nginx.service.d
mq50-pacemaker.conf
Active: active (running) since Wed 2023-04-26 15:51:58 JST; 3min 29s ago
Process: 8064 ExecStart=/usr/sbin/nginx (code=exited, status=0/SUCCESS)
Process: 8062 ExecStartPre=/usr/sbin/nginx -t (code=exited, status=0/SUCCESS)
Process: 8060 ExecStartPre=/usr/bin/rm -f /run/nginx.pid (code=exited, status>
Main PID: 8065 (nginx)
Tasks: 3 (limit: 4588)
Memory: 5.6M
CGroup: /system.slice/nginx.service
tq8065 nginx: master process /usr/sbin/nginx
tq8066 nginx: worker process
mq8067 nginx: worker process
Apr 12 15:51:58 pm-test2 systemd[1]: Starting Cluster Controlled nginx...
Apr 12 15:51:58 pm-test2 nginx[8062]: nginx: the configuration file /etc/nginx/>
Apr 12 15:51:58 pm-test2 nginx[8062]: nginx: configuration file /etc/nginx/ngin>
Apr 12 15:51:58 pm-test2 systemd[1]: Started Cluster Controlled nginx.
Virtual IP で、Webページにアクセスしてみます。
# curl http://192.168.1.178/test.html <!DOCTYPE html> <html> <head> <meta charset="UTF-8" /> <title>Test Page</title> </head> <body> <h1>Test Page</h1> test page on pm-test2. </body> </html>
↑pm-test2 にアクセスしています。
無事、フェイルオーバーを確認できました。
ここで、pm-test1 にフェイルバックする(切り戻す)には、pcs resource clear コマンドでフェイルオーバー時に作成された制約(constraint)を削除し、pcs resource move を実行します。
まず、制約を確認します。
(pm-test1 or pm-test2)
# pcs constraint
Location Constraints:
Resource: rg01
Enabled on:
Node: pm-test2 (score:INFINITY) (role:Started)
Constraint: location-rg01
Rule: boolean-op=or score=-INFINITY
Expression: pingd lt 1
Expression: not_defined pingd
Ordering Constraints:
Colocation Constraints:
Ticket Constraints:
↑リソースグループ rg01 の Constraints(制約)が「Enable on」となっています。
「Constraint: location-rg01」は、もともと設定してあった、pingdのロケーションの制約設定です。
pcs resource clear コマンドで、rg01の制約を削除します。
# pcs resource clear rg01 Removing constraint: cli-prefer-rg01
再度、制約を確認します。
# pcs constraint
Location Constraints:
Resource: rg01
Constraint: location-rg01
Rule: boolean-op=or score=-INFINITY
Expression: pingd lt 1
Expression: not_defined pingd
Ordering Constraints:
Colocation Constraints:
Ticket Constraints:
↑リソースグループ rg01 の Constraints(制約)「Enable on」がなくなりました。
再度、Pacemakerの状態を確認します。
# pcs status
Cluster name: cluster01
Status of pacemakerd: 'Pacemaker is running' (last updated 2023-04-12 16:02:18 +09:00)
Cluster Summary:
* Stack: corosync
* Current DC: pm-test1 (version 2.1.4-5.el8_7.2-dc6eb4362e) - partition with quorum
* Last updated: Wed Apr 12 16:02:19 2023
* Last change: Wed Apr 12 15:59:45 2023 by root via crm_resource on pm-test2
* 2 nodes configured
* 4 resource instances configured
Node List:
* Online: [ pm-test1 pm-test2 ]
Full List of Resources:
* Resource Group: rg01:
* rs-vip (ocf::heartbeat:IPaddr2): Started pm-test2
* rs-systemd-nginx (systemd:nginx): Started pm-test2
* Clone Set: rs-ping-gw-clone [rs-ping-gw]:
* Started: [ pm-test1 pm-test2 ]
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
pcsd: active/enabled
↑冒頭のWarningメッセージがなくなりました。
pcs resource move コマンドで、リソースグループ rg01 を pm-test1 にフェイルバックします。
# pcs resource move rg01 pm-test1 Warning: A move constraint has been created and the resource 'rg01' may or may not move depending on other configuration
数秒で、pm-test1 へのフェイルオーバーが完了します。
Pacemakerの状態を確認します。
# pcs status
Cluster name: cluster01
WARNINGS:
Following resources have been moved and their move constraints are still in place: 'rg01'
Run 'pcs constraint location' or 'pcs resource clear <resource id>' to view or remove the constraints, respectively
Status of pacemakerd: 'Pacemaker is running' (last updated 2023-04-12 16:05:32 +09:00)
Cluster Summary:
* Stack: corosync
* Current DC: pm-test1 (version 2.1.4-5.el8_7.2-dc6eb4362e) - partition with quorum
* Last updated: Wed Apr 12 16:05:32 2023
* Last change: Wed Apr 12 16:05:21 2023 by root via crm_resource on pm-test1
* 2 nodes configured
* 4 resource instances configured
Node List:
* Online: [ pm-test1 pm-test2 ]
Full List of Resources:
* Resource Group: rg01:
* rs-vip (ocf::heartbeat:IPaddr2): Started pm-test1
* rs-systemd-nginx (systemd:nginx): Started pm-test1
* Clone Set: rs-ping-gw-clone [rs-ping-gw]:
* Started: [ pm-test1 pm-test2 ]
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
pcsd: active/enabled
↑pm-test1 がアクティブ、pm-test2 がスタンバイ(standby)となっていることがわかります。
また、先ほどフェイルオーバーしたときと同様に、冒頭で制約に関するWarningメッセージが出力されています。
Virtual IP で、Webページにアクセスしてみます。
# curl http://192.168.1.178/test.html <!DOCTYPE html> <html> <head> <meta charset="UTF-8" /> <title>Test Page</title> </head> <body> <h1>Test Page</h1> test page on pm-test1. </body> </html>
↑pm-test2 にアクセスしています。
無事、フェイルオーバーを確認できました。
このとき、pm-test2 のNginxは停止しています。
# ps aux | grep nginx root 14037 0.0 0.1 221940 1168 pts/1 S+ 16:06 0:00 grep --color=auto nginx
制約が存在することを確認し、削除します。
# pcs constraint
Location Constraints:
Resource: rg01
Enabled on:
Node: pm-test1 (score:INFINITY) (role:Started)
Constraint: location-rg01
Rule: boolean-op=or score=-INFINITY
Expression: pingd lt 1
Expression: not_defined pingd
Ordering Constraints:
Colocation Constraints:
Ticket Constraints:
# pcs resource clear rg01
Removing constraint: cli-prefer-rg01
# pcs constraint
Location Constraints:
Resource: rg01
Constraint: location-rg01
Rule: boolean-op=or score=-INFINITY
Expression: pingd lt 1
Expression: not_defined pingd
Ordering Constraints:
Colocation Constraints:
Ticket Constraints:
再度、Pacemakerの状態を確認します。
# pcs status
Cluster name: cluster01
Status of pacemakerd: 'Pacemaker is running' (last updated 2023-04-12 16:09:43 +09:00)
Cluster Summary:
* Stack: corosync
* Current DC: pm-test1 (version 2.1.4-5.el8_7.2-dc6eb4362e) - partition with quorum
* Last updated: Wed Apr 12 16:09:43 2023
* Last change: Wed Apr 12 16:08:50 2023 by root via crm_resource on pm-test2
* 2 nodes configured
* 4 resource instances configured
Node List:
* Online: [ pm-test1 pm-test2 ]
Full List of Resources:
* Resource Group: rg01:
* rs-vip (ocf::heartbeat:IPaddr2): Started pm-test1
* rs-systemd-nginx (systemd:nginx): Started pm-test1
* Clone Set: rs-ping-gw-clone [rs-ping-gw]:
* Started: [ pm-test1 pm-test2 ]
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
pcsd: active/enabled
↑冒頭のWarningメッセージがなくなりました。
これで、pm-test1 から pm-test2 へのフェイルオーバーと、pm-test2 から pm-test1 へのフェイルバック(切り戻し)は完了です。
手動フェイルオーバー方法2. pcs node standby コマンドでアクティブなノードをスタンバイ状態とする
まず、Pacemakerで、pm-test1 がアクティブになっていることを確認します。
(pm-test1)
# pcs status
Cluster name: cluster01
Status of pacemakerd: 'Pacemaker is running' (last updated 2023-04-13 17:59:13 +09:00)
Cluster Summary:
* Stack: corosync
* Current DC: pm-test1 (version 2.1.4-5.el8_7.2-dc6eb4362e) - partition with quorum
* Last updated: Fri Apr 14 17:59:14 2023
* Last change: Thu Apr 13 17:40:33 2023 by hacluster via crmd on pm-test1
* 2 nodes configured
* 4 resource instances configured
Node List:
* Online: [ pm-test1 pm-test2 ]
Full List of Resources:
* Resource Group: rg01:
* rs-vip (ocf::heartbeat:IPaddr2): Started pm-test1
* rs-systemd-nginx (systemd:nginx): Started pm-test1
* Clone Set: rs-ping-gw-clone [rs-ping-gw]:
* Started: [ pm-test1 pm-test2 ]
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
pcsd: active/enabled
↑「Node List:」で、pm-test1, pm-test2 が2台とも Online となっています。
また、「Full List of Resources:」で、pm-test1 がアクティブとなっています。
pm-test2 にフェイルオーバーするため、pcs node standby コマンドで、pm-test1 をスタンバイ状態とします。
# pcs node standby pm-test1
数秒で、pm-test2 へのフェイルオーバーが完了します。
このとき、pm-test1 のNginxは停止しました。
# systemctl status nginx ● nginx.service - The nginx HTTP and reverse proxy server Loaded: loaded (/usr/lib/systemd/system/nginx.service; disabled; vendor pres> Active: inactive (dead) Apr 13 17:56:28 pm-test1 systemd[1]: Starting Cluster Controlled nginx... Apr 13 17:56:28 pm-test1 nginx[3215]: nginx: the configuration file /etc/nginx/> Apr 13 17:56:28 pm-test1 nginx[3215]: nginx: configuration file /etc/nginx/ngin> Apr 13 17:56:28 pm-test1 systemd[1]: Started Cluster Controlled nginx. Apr 13 18:03:18 pm-test1 systemd[1]: Stopping The nginx HTTP and reverse proxy > Apr 13 18:03:18 pm-test1 systemd[1]: nginx.service: Succeeded. Apr 13 18:03:18 pm-test1 systemd[1]: Stopped The nginx HTTP and reverse proxy s>
pm-test2 で操作してみます。
Pacemakerの状態を確認します。
(pm-test2)
# pcs status
Cluster name: cluster01
Status of pacemakerd: 'Pacemaker is running' (last updated 2023-04-13 18:03:24 +09:00)
Cluster Summary:
* Stack: corosync
* Current DC: pm-test1 (version 2.1.4-5.el8_7.2-dc6eb4362e) - partition with quorum
* Last updated: Thu Apr 13 18:03:25 2023
* Last change: Thu Apr 13 18:03:18 2023 by root via cibadmin on pm-test1
* 2 nodes configured
* 4 resource instances configured
Node List:
* Node pm-test1: standby
* Online: [ pm-test2 ]
Full List of Resources:
* Resource Group: rg01:
* rs-vip (ocf::heartbeat:IPaddr2): Started pm-test2
* rs-systemd-nginx (systemd:nginx): Started pm-test2
* Clone Set: rs-ping-gw-clone [rs-ping-gw]:
* Started: [ pm-test2 ]
* Stopped: [ pm-test1 ]
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
pcsd: active/enabled
↑pm-test1 がスタンバイ(standby)、pm-test2 がアクティブとなっていることがわかります。
Nginxのサービスステータスを確認すると、Nginxが起動しています。
# systemctl status nginx
● nginx.service - Cluster Controlled nginx
Loaded: loaded (/usr/lib/systemd/system/nginx.service; disabled; vendor pres>
Drop-In: /run/systemd/system/nginx.service.d
mq50-pacemaker.conf
Active: active (running) since Fri 2023-04-14 18:03:21 JST; 19min ago
Process: 5057 ExecStart=/usr/sbin/nginx (code=exited, status=0/SUCCESS)
Process: 5055 ExecStartPre=/usr/sbin/nginx -t (code=exited, status=0/SUCCESS)
Process: 5053 ExecStartPre=/usr/bin/rm -f /run/nginx.pid (code=exited, status>
Main PID: 5058 (nginx)
Tasks: 3 (limit: 4588)
Memory: 11.7M
CGroup: /system.slice/nginx.service
tq5058 nginx: master process /usr/sbin/nginx
tq5059 nginx: worker process
mq5060 nginx: worker process
Apr 13 18:03:21 pm-test2 systemd[1]: Starting Cluster Controlled nginx...
Apr 13 18:03:21 pm-test2 nginx[5055]: nginx: the configuration file /etc/nginx/>
Apr 13 18:03:21 pm-test2 nginx[5055]: nginx: configuration file /etc/nginx/ngin>
Apr 13 18:03:21 pm-test2 systemd[1]: Started Cluster Controlled nginx.
Virtual IP で、Webページにアクセスしてみます。
# curl http://192.168.1.178/test.html <!DOCTYPE html> <html> <head> <meta charset="UTF-8" /> <title>Test Page</title> </head> <body> <h1>Test Page</h1> test page on pm-test2. </body> </html>
↑pm-test2 にアクセスしています。
無事、フェイルオーバーを確認できました。
ここで、pm-test1 にフェイルバックする(切り戻す)には、pm-test1 のスタンバイを解除して、pm-test2 をスタンバイ状態とします。
pcs node unstandby コマンドで、pm-test1 のスタンバイを解除します。
(pm-test1 or pm-test2)
# pcs node unstandby pm-test1
Pacemakerの状態を確認します。
# pcs status
Cluster name: cluster01
Status of pacemakerd: 'Pacemaker is running' (last updated 2023-04-13 18:28:18 +09:00)
Cluster Summary:
* Stack: corosync
* Current DC: pm-test2 (version 2.1.4-5.el8_7.2-dc6eb4362e) - partition with quorum
* Last updated: Thu Apr 13 18:28:19 2023
* Last change: Thu Apr 13 18:27:49 2023 by root via cibadmin on pm-test2
* 2 nodes configured
* 4 resource instances configured
Node List:
* Online: [ pm-test1 pm-test2 ]
Full List of Resources:
* Resource Group: rg01:
* rs-vip (ocf::heartbeat:IPaddr2): Started pm-test2
* rs-systemd-nginx (systemd:nginx): Started pm-test2
* Clone Set: rs-ping-gw-clone [rs-ping-gw]:
* Started: [ pm-test1 pm-test2 ]
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
pcsd: active/enabled
↑「Node List:」が2台とも Online となりました。
フェイルバックするため、pcs node standby コマンドで、pm-test2 をスタンバイ状態とします。
# pcs node standby pm-test2
数秒で pm-test1 へのフェイルオーバーが完了します。
Pacemakerの状態を確認します。
# pcs status
Cluster name: cluster01
Status of pacemakerd: 'Pacemaker is running' (last updated 2023-04-14 18:29:33 +09:00)
Cluster Summary:
* Stack: corosync
* Current DC: pm-test2 (version 2.1.4-5.el8_7.2-dc6eb4362e) - partition with quorum
* Last updated: Thu Apr 13 18:29:34 2023
* Last change: Thu Apr 13 18:29:27 2023 by root via cibadmin on pm-test2
* 2 nodes configured
* 4 resource instances configured
Node List:
* Node pm-test2: standby
* Online: [ pm-test1 ]
Full List of Resources:
* Resource Group: rg01:
* rs-vip (ocf::heartbeat:IPaddr2): Started pm-test1
* rs-systemd-nginx (systemd:nginx): Started pm-test1
* Clone Set: rs-ping-gw-clone [rs-ping-gw]:
* Started: [ pm-test1 ]
* Stopped: [ pm-test2 ]
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
pcsd: active/enabled
↑pm-test1 がアクティブ、pm-test2 がスタンバイ(standby)となっていることがわかります。
Virtual IP で、Webページにアクセスしてみます。
# curl http://192.168.1.178/test.html <!DOCTYPE html> <html> <head> <meta charset="UTF-8" /> <title>Test Page</title> </head> <body> <h1>Test Page</h1> test page on pm-test1. </body> </html>
↑pm-test1 にアクセスしています。
最後に、pcs node unstandby コマンドで、pm-test2 のスタンバイ状態を解除します。
# pcs node unstandby pm-test2
# pcs status
Cluster name: cluster01
Status of pacemakerd: 'Pacemaker is running' (last updated 2023-04-14 18:35:42 +09:00)
Cluster Summary:
* Stack: corosync
* Current DC: pm-test1 (version 2.1.4-5.el8_7.2-dc6eb4362e) - partition with quorum
* Last updated: Thu Apr 13 18:35:43 2023
* Last change: Thu Apr 13 18:32:17 2023 by root via cibadmin on pm-test2
* 2 nodes configured
* 4 resource instances configured
Node List:
* Online: [ pm-test1 pm-test2 ]
Full List of Resources:
* Resource Group: rg01:
* rs-vip (ocf::heartbeat:IPaddr2): Started pm-test1
* rs-systemd-nginx (systemd:nginx): Started pm-test1
* Clone Set: rs-ping-gw-clone [rs-ping-gw]:
* Started: [ pm-test1 pm-test2 ]
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
pcsd: active/enabled
↑「Node List」が2台とも Online となりました。
これで、pm-test1 から pm-test2 へのフェイルオーバーと、pm-test2 から pm-test1 へのフェイルバック(切り戻し)は完了です。
手動フェイルオーバー方法3. アクティブなノードでpacemakerサービスを停止する
まず、Pacemakerで、pm-test1 がアクティブになっていることを確認します。
(pm-test1)
# pcs status
Cluster name: cluster01
Status of pacemakerd: 'Pacemaker is running' (last updated 2023-04-17 18:04:58 +09:00)
Cluster Summary:
* Stack: corosync
* Current DC: pm-test2 (version 2.1.4-5.el8_7.2-dc6eb4362e) - partition with quorum
* Last updated: Mon Apr 17 18:04:59 2023
* Last change: Mon Apr 17 18:04:36 2023 by root via cibadmin on pm-test2
* 2 nodes configured
* 4 resource instances configured
Node List:
* Online: [ pm-test1 pm-test2 ]
Full List of Resources:
* Resource Group: rg01:
* rs-vip (ocf::heartbeat:IPaddr2): Started pm-test1
* rs-systemd-nginx (systemd:nginx): Started pm-test1
* Clone Set: rs-ping-gw-clone [rs-ping-gw]:
* Started: [ pm-test1 pm-test2 ]
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
pcsd: active/enabled
↑「Node List:」で、pm-test1, pm-test2 が2台とも Online となっています。
また、「Full List of Resources:」で、pm-test1 がアクティブとなっています。
pm-test2 にフェイルオーバーするため、pm-test1 で、pacemakerサービスを停止します。
# systemctl stop pacemaker
# systemctl status pacemaker
● pacemaker.service - Pacemaker High Availability Cluster Manager
Loaded: loaded (/usr/lib/systemd/system/pacemaker.service; enabled; vendor p>
Active: inactive (dead) since Mon 2023-04-17 18:20:46 JST; 1s ago
Docs: man:pacemakerd
https://clusterlabs.org/pacemaker/doc/
Process: 9855 ExecStart=/usr/sbin/pacemakerd (code=exited, status=0/SUCCESS)
Main PID: 9855 (code=exited, status=0/SUCCESS)
Apr 17 18:20:46 pm-test1 pacemakerd[9855]: notice: Stopping pacemaker-execd
Apr 17 18:20:46 pm-test1 pacemakerd[9855]: notice: Stopping pacemaker-fenced
Apr 17 18:20:46 pm-test1 pacemaker-fenced[9857]: notice: Caught 'Terminated' s>
Apr 17 18:20:46 pm-test1 pacemakerd[9855]: notice: Stopping pacemaker-based
Apr 17 18:20:46 pm-test1 pacemaker-based[9856]: notice: Caught 'Terminated' si>
Apr 17 18:20:46 pm-test1 pacemaker-based[9856]: notice: Disconnected from Coro>
Apr 17 18:20:46 pm-test1 pacemaker-based[9856]: notice: Disconnected from Coro>
Apr 17 18:20:46 pm-test1 pacemakerd[9855]: notice: Shutdown complete
Apr 17 18:20:46 pm-test1 systemd[1]: pacemaker.service: Succeeded.
Apr 17 18:20:46 pm-test1 systemd[1]: Stopped Pacemaker High Availability Cluste>
数秒で、pm-test2 へのフェイルオーバーが完了します。
pm-test1 ではPacemakerが起動していないので、pm-test2 でPacemakerの状態を確認します。
(pm-test2)
# pcs status
Cluster name: cluster01
Status of pacemakerd: 'Pacemaker is running' (last updated 2023-04-17 18:21:31 +09:00)
Cluster Summary:
* Stack: corosync
* Current DC: pm-test2 (version 2.1.4-5.el8_7.2-dc6eb4362e) - partition with quorum
* Last updated: Mon Apr 17 18:21:31 2023
* Last change: Mon Apr 17 18:04:36 2023 by root via cibadmin on pm-test2
* 2 nodes configured
* 4 resource instances configured
Node List:
* Online: [ pm-test2 ]
* OFFLINE: [ pm-test1 ]
Full List of Resources:
* Resource Group: rg01:
* rs-vip (ocf::heartbeat:IPaddr2): Started pm-test2
* rs-systemd-nginx (systemd:nginx): Started pm-test2
* Clone Set: rs-ping-gw-clone [rs-ping-gw]:
* Started: [ pm-test2 ]
* Stopped: [ pm-test1 ]
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
pcsd: active/enabled
↑「Node List:」で pm-test1 が OFFLINE となっています。
また、「Full List of Resources:」で、pm-test2 がアクティブとなっています。
Nginxのサービスステータスを確認すると、Nginxが起動しています。
# systemctl status nginx
● nginx.service - Cluster Controlled nginx
Loaded: loaded (/usr/lib/systemd/system/nginx.service; disabled; vendor pres>
Drop-In: /run/systemd/system/nginx.service.d
mq50-pacemaker.conf
Active: active (running) since Mon 2023-04-17 18:20:46 JST; 4min 6s ago
Process: 6697 ExecStart=/usr/sbin/nginx (code=exited, status=0/SUCCESS)
Process: 6695 ExecStartPre=/usr/sbin/nginx -t (code=exited, status=0/SUCCESS)
Process: 6691 ExecStartPre=/usr/bin/rm -f /run/nginx.pid (code=exited, status>
Main PID: 6698 (nginx)
Tasks: 3 (limit: 4588)
Memory: 9.3M
CGroup: /system.slice/nginx.service
tq6698 nginx: master process /usr/sbin/nginx
tq6699 nginx: worker process
mq6700 nginx: worker process
Apr 17 18:20:46 pm-test2 systemd[1]: Starting Cluster Controlled nginx...
Apr 17 18:20:46 pm-test2 nginx[6695]: nginx: the configuration file /etc/nginx/>
Apr 17 18:20:46 pm-test2 nginx[6695]: nginx: configuration file /etc/nginx/ngin>
Apr 17 18:20:46 pm-test2 systemd[1]: Started Cluster Controlled nginx.
Virtual IP で、Webページにアクセスしてみます。
# curl http://192.168.1.178/test.html <!DOCTYPE html> <html> <head> <meta charset="UTF-8" /> <title>Test Page</title> </head> <body> <h1>Test Page</h1> test page on pm-test2. </body> </html>
↑pm-test2 にアクセスしています。
無事、フェイルオーバーを確認できました。
ここで、pm-test1 にフェイルバックする(切り戻す)には、
pm-test1 で pacemaker サービスを起動
→ pm-test2 で pacemaker サービスを停止
→ pm-test2 で pacemaker サービスを起動
を順に実施します。
まず、pm-test1 で pacemaker サービスを起動します。
(pm-test1)
# systemctl start pacemaker
Pacemakerの状態を確認します。
# pcs status
Cluster name: cluster01
Status of pacemakerd: 'Pacemaker is running' (last updated 2023-04-17 18:26:46 +09:00)
Cluster Summary:
* Stack: corosync
* Current DC: pm-test2 (version 2.1.4-5.el8_7.2-dc6eb4362e) - partition with quorum
* Last updated: Mon Apr 17 18:26:46 2023
* Last change: Mon Apr 17 18:04:36 2023 by root via cibadmin on pm-test2
* 2 nodes configured
* 4 resource instances configured
Node List:
* Online: [ pm-test1 pm-test2 ]
Full List of Resources:
* Resource Group: rg01:
* rs-vip (ocf::heartbeat:IPaddr2): Started pm-test2
* rs-systemd-nginx (systemd:nginx): Started pm-test2
* Clone Set: rs-ping-gw-clone [rs-ping-gw]:
* Started: [ pm-test1 pm-test2 ]
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
pcsd: active/enabled
↑「Node List:」で、pm-test1, pm-test2 が2台とも Online となりました。
※「Failed Resource Actions:」は存在しないので、pcs resource cleanup は不要です。
フェイルバックするため、pm-test2 で pacemaker サービスを停止します。
(pm-test2)
# systemctl stop pacemaker
数秒で pm-test1 へのフェイルオーバーが完了します。
pm-test2 ではPacemakerが起動していないので、pm-test1 でPacemakerの状態を確認します。
(pm-test1)
# pcs status
Cluster name: cluster01
Status of pacemakerd: 'Pacemaker is running' (last updated 2023-04-17 18:31:40 +09:00)
Cluster Summary:
* Stack: corosync
* Current DC: pm-test1 (version 2.1.4-5.el8_7.2-dc6eb4362e) - partition with quorum
* Last updated: Mon Apr 17 18:31:40 2023
* Last change: Mon Apr 17 18:04:36 2023 by root via cibadmin on pm-test2
* 2 nodes configured
* 4 resource instances configured
Node List:
* Online: [ pm-test1 ]
* OFFLINE: [ pm-test2 ]
Full List of Resources:
* Resource Group: rg01:
* rs-vip (ocf::heartbeat:IPaddr2): Started pm-test1
* rs-systemd-nginx (systemd:nginx): Started pm-test1
* Clone Set: rs-ping-gw-clone [rs-ping-gw]:
* Started: [ pm-test1 ]
* Stopped: [ pm-test2 ]
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
pcsd: active/enabled
↑「Node List:」で pm-test2 が OFFLINE となっています。
また、「Full List of Resources:」で、pm-test1 がアクティブとなっています。
Virtual IP で、Webページにアクセスしてみます。
# curl http://192.168.1.178/test.html <!DOCTYPE html> <html> <head> <meta charset="UTF-8" /> <title>Test Page</title> </head> <body> <h1>Test Page</h1> test page on pm-test1. </body> </html>
↑pm-test1 にアクセスしています。
無事、フェイルバックを確認できました。
最後に、pm-test2 で、pacemaker サービスを起動します。
(pm-test2)
# systemctl start pacemaker
Pacemakerの状態を確認します。
# pcs status
Cluster name: cluster01
Status of pacemakerd: 'Pacemaker is running' (last updated 2023-04-17 18:35:07 +09:00)
Cluster Summary:
* Stack: corosync
* Current DC: pm-test1 (version 2.1.4-5.el8_7.2-dc6eb4362e) - partition with quorum
* Last updated: Mon Apr 17 18:35:08 2023
* Last change: Mon Apr 17 18:04:36 2023 by root via cibadmin on pm-test2
* 2 nodes configured
* 4 resource instances configured
Node List:
* Online: [ pm-test1 pm-test2 ]
Full List of Resources:
* Resource Group: rg01:
* rs-vip (ocf::heartbeat:IPaddr2): Started pm-test1
* rs-systemd-nginx (systemd:nginx): Started pm-test1
* Clone Set: rs-ping-gw-clone [rs-ping-gw]:
* Started: [ pm-test1 pm-test2 ]
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
pcsd: active/enabled
↑「Node List:」で pm-test1, pm-test2 が2台とも Online となりました。
手動フェイルオーバーの3つの方法を試してみましたが、1,2の方法は、フェイルオーバー後に制約の削除やスタンバイ状態の解除が必要です。
3の方法が一番簡単ですね。
6. 想定する障害と具体的なPacemakerの動作
Pacemakerによりサービス継続が可能な障害のケースとしては、以下のA~Dが考えられます。
A. Nginxサービス障害
B. ネットワーク切断
C. サーバーOSダウン
D. Pacemakerの不具合発生
A, B, Cのケースでは、
不具合が発生したノードで、不具合が解消したことが確認できたら、そのノードで pcs resource cleanup コマンドによりPacemakerのエラー状態をクリアします。
その後、フェイルバック(切り戻し)が必要であれば、前述の「手動フェイルオーバー手順」に従って、切り戻しの操作を行います。
以下、障害を発生させることが可能であれば、試してみます。
想定する障害A. Nginxサービス障害
(想定する動作)
- Nginxプロセスが終了した場合、Pacemakerはフェイルオーバーする前にまず、Nginxサービスの起動を試みる。
- 監視間隔として設定されている、60秒程度でNginxが起動する。
- Nginxを起動できなければ、自動フェイルオーバーする。
実際に試してみます。
まず、Pacemakerの状態を確認します。
# pcs status
Cluster name: cluster01
Status of pacemakerd: 'Pacemaker is running' (last updated 2023-04-18 18:49:01 +09:00)
Cluster Summary:
* Stack: corosync
* Current DC: pm-test2 (version 2.1.4-5.el8_7.2-dc6eb4362e) - partition with quorum
* Last updated: Tue Apr 18 18:49:02 2023
* Last change: Tue Apr 18 18:48:56 2023 by hacluster via crmd on pm-test1
* 2 nodes configured
* 4 resource instances configured
Node List:
* Online: [ pm-test1 pm-test2 ]
Full List of Resources:
* Resource Group: rg01:
* rs-vip (ocf::heartbeat:IPaddr2): Started pm-test1
* rs-systemd-nginx (systemd:nginx): Started pm-test1
* Clone Set: rs-ping-gw-clone [rs-ping-gw]:
* Started: [ pm-test1 pm-test2 ]
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
pcsd: active/enabled
↑Virtual IPとNginxリソースが、pm-test1 でアクティブとなっています。
pm-test1で、killallコマンドで、Nginxプロセスを強制終了します。
(pm-test1)
# date; killall -9 nginx Tue Apr 18 18:49:59 JST 2023 # ps aux | grep nginx root 7286 0.0 0.1 221940 1168 pts/1 S+ 18:45 0:00 grep --color=auto nginx
↑nginxプロセスが存在しないことが確認できました。
短時間で定期的に pcs status コマンドを実行し、Pacemaker の状態を確認します。
# pcs status
Cluster name: cluster01
Status of pacemakerd: 'Pacemaker is running' (last updated 2023-04-18 18:50:10 +09:00)
Cluster Summary:
* Stack: corosync
* Current DC: pm-test2 (version 2.1.4-5.el8_7.2-dc6eb4362e) - partition with quorum
* Last updated: Tue Apr 18 18:50:10 2023
* Last change: Tue Apr 18 18:48:56 2023 by hacluster via crmd on pm-test1
* 2 nodes configured
* 4 resource instances configured
Node List:
* Online: [ pm-test1 pm-test2 ]
Full List of Resources:
* Resource Group: rg01:
* rs-vip (ocf::heartbeat:IPaddr2): Started pm-test1
* rs-systemd-nginx (systemd:nginx): Started pm-test1
* Clone Set: rs-ping-gw-clone [rs-ping-gw]:
* Started: [ pm-test1 pm-test2 ]
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
pcsd: active/enabled
# pcs status
Cluster name: cluster01
Status of pacemakerd: 'Pacemaker is running' (last updated 2023-04-18 18:50:57 +09:00)
Cluster Summary:
* Stack: corosync
* Current DC: pm-test2 (version 2.1.4-5.el8_7.2-dc6eb4362e) - partition with quorum
* Last updated: Tue Apr 18 18:50:57 2023
* Last change: Tue Apr 18 18:48:56 2023 by hacluster via crmd on pm-test1
* 2 nodes configured
* 4 resource instances configured
Node List:
* Online: [ pm-test1 pm-test2 ]
Full List of Resources:
* Resource Group: rg01:
* rs-vip (ocf::heartbeat:IPaddr2): Started pm-test1
* rs-systemd-nginx (systemd:nginx): FAILED pm-test1
* Clone Set: rs-ping-gw-clone [rs-ping-gw]:
* Started: [ pm-test1 pm-test2 ]
Failed Resource Actions:
* rs-systemd-nginx_monitor_60000 on pm-test1 'not running' (7): call=31, status='complete', exitreason='inactive', last-rc-change='Tue Apr 18 18:50:57 2023', queued=0ms, exec=0ms
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
pcsd: active/enabled
# pcs status
Cluster name: cluster01
Status of pacemakerd: 'Pacemaker is running' (last updated 2023-04-18 18:51:21 +09:00)
Cluster Summary:
* Stack: corosync
* Current DC: pm-test2 (version 2.1.4-5.el8_7.2-dc6eb4362e) - partition with quorum
* Last updated: Tue Apr 18 18:51:22 2023
* Last change: Tue Apr 18 18:48:56 2023 by hacluster via crmd on pm-test1
* 2 nodes configured
* 4 resource instances configured
Node List:
* Online: [ pm-test1 pm-test2 ]
Full List of Resources:
* Resource Group: rg01:
* rs-vip (ocf::heartbeat:IPaddr2): Started pm-test1
* rs-systemd-nginx (systemd:nginx): Started pm-test1
* Clone Set: rs-ping-gw-clone [rs-ping-gw]:
* Started: [ pm-test1 pm-test2 ]
Failed Resource Actions:
* rs-systemd-nginx_monitor_60000 on pm-test1 'not running' (7): call=31, status='complete', exitreason='inactive', last-rc-change='Tue Apr 18 18:50:57 2023', queued=0ms, exec=0ms
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
pcsd: active/enabled
↑リソース rs-systemd-nginx が一時的に「FAILED pm-test1」となりましたが、その後、「Started pm-test1」に戻りました。
Virtual IP で、Webページにアクセスしてみます。
# curl http://192.168.1.178/test.html <!DOCTYPE html> <html> <head> <meta charset="UTF-8" /> <title>Test Page</title> </head> <body> <h1>Test Page</h1> test page on pm-test1. </body> </html>
↑変わらず、pm-test1 のほうにアクセスしています。
Nginxのプロセス、サービスを確認してみます。
# ps aux | grep nginx
root 9576 0.0 0.2 103392 2124 ? Ss 18:50 0:00 nginx: master process /usr/sbin/nginx
nginx 9577 0.0 0.9 136036 7844 ? S 18:50 0:00 nginx: worker process
nginx 9578 0.0 0.9 136036 7844 ? S 18:50 0:00 nginx: worker process
root 9914 0.0 0.1 221940 1204 pts/1 S+ 18:51 0:00 grep --color=auto nginx
# systemctl status nginx
● nginx.service - Cluster Controlled nginx
Loaded: loaded (/usr/lib/systemd/system/nginx.service; disabled; vendor preset>
Drop-In: /run/systemd/system/nginx.service.d
mq50-pacemaker.conf
Active: active (running) since Wed 2023-04-18 18:51:00 JST; 1min 43s ago
Process: 9575 ExecStart=/usr/sbin/nginx (code=exited, status=0/SUCCESS)
Process: 9573 ExecStartPre=/usr/sbin/nginx -t (code=exited, status=0/SUCCESS)
Process: 9570 ExecStartPre=/usr/bin/rm -f /run/nginx.pid (code=exited, status=0>
Main PID: 9576 (nginx)
Tasks: 3 (limit: 4588)
Memory: 5.8M
CGroup: /system.slice/nginx.service
tq9576 nginx: master process /usr/sbin/nginx
tq9577 nginx: worker process
mq9578 nginx: worker process
Apr 18 18:51:00 pm-test1 systemd[1]: Starting Cluster Controlled nginx...
Apr 18 18:51:00 pm-test1 nginx[9573]: nginx: the configuration file /etc/nginx/ng>
Apr 18 18:51:00 pm-test1 nginx[9573]: nginx: configuration file /etc/nginx/nginx.>
Apr 18 18:51:00 pm-test1 systemd[1]: nginx.service: Failed to parse PID from file>
Apr 18 18:51:00 pm-test1 systemd[1]: Started Cluster Controlled nginx
↑Nginxが、18:51:00 に起動したことがわかります。
プロセスを kill したのは 18:49:59 ですから、1分01秒で復旧しました。
Nginxサービスの監視間隔は60秒ですので、いいところでしょう。
pcs status コマンドの出力結果で
「Failed Resource Actions:」で、リソース稼働エラーの検知が表示されています。
問題なければ、pcs resource cleanup コマンドでリソースの状態を正常に戻します。
# pcs resource cleanup
Cleaned up all resources on all nodes
Waiting for 1 reply from the controller
... got reply (done)
# pcs status
Cluster name: cluster01
Status of pacemakerd: 'Pacemaker is running' (last updated 2023-04-18 19:02:12 +09:00)
Cluster Summary:
* Stack: corosync
* Current DC: pm-test2 (version 2.1.4-5.el8_7.2-dc6eb4362e) - partition with quorum
* Last updated: Tue Apr 18 19:02:13 2023
* Last change: Tue Apr 18 19:02:00 2023 by hacluster via crmd on pm-test1
* 2 nodes configured
* 4 resource instances configured
Node List:
* Online: [ pm-test1 pm-test2 ]
Full List of Resources:
* Resource Group: rg01:
* rs-vip (ocf::heartbeat:IPaddr2): Started pm-test1
* rs-systemd-nginx (systemd:nginx): Started pm-test1
* Clone Set: rs-ping-gw-clone [rs-ping-gw]:
* Started: [ pm-test1 pm-test2 ]
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
pcsd: active/enabled
↑「Failed Resource Actions:」がなくなり、正常な状態となりました。
想定どおりの動作を確認できました。
なお、「Nginxの起動を試みて、起動できなければ、自動フェイルオーバーする」については、Nginxプロセスを強制終了する前に、一時的に nginx.conf をリネームするなどの(イリーガルな)方法で、動作確認できます。
想定する障害B. ネットワーク切断
(想定する動作)
- Pacemakerは自動フェイルオーバーする。
- 数秒程度で切り替わる。
実際に試してみます。
まず、Pacemakerの状態を確認します。
# pcs status
Cluster name: cluster01
Status of pacemakerd: 'Pacemaker is running' (last updated 2023-04-19 12:03:20 +09:00)
Cluster Summary:
* Stack: corosync
* Current DC: pm-test1 (version 2.1.4-5.el8_7.2-dc6eb4362e) - partition with quorum
* Last updated: Wed Apr 19 12:03:21 2023
* Last change: Wed Apr 19 12:02:29 2023 by hacluster via crmd on pm-test1
* 2 nodes configured
* 4 resource instances configured
Node List:
* Online: [ pm-test1 pm-test2 ]
Full List of Resources:
* Resource Group: rg01:
* rs-vip (ocf::heartbeat:IPaddr2): Started pm-test1
* rs-systemd-nginx (systemd:nginx): Started pm-test1
* Clone Set: rs-ping-gw-clone [rs-ping-gw]:
* Started: [ pm-test1 pm-test2 ]
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
pcsd: active/enabled
↑Virtual IPとNginxリソースが、pm-test1 でアクティブとなっています。
pm-test1 で、ネットワークマネージャーのコマンド nmcli でデバイス情報を確認し、ネットワークを切断します。
(pm-test1)
# nmcli device DEVICE TYPE STATE CONNECTION eth0 ethernet connected System eth0 lo loopback unmanaged -- # date; nmcli connect down 'System eth0' Wed Apr 19 12:07:31 JST 2023
pm-test1 にSSH接続していれば、この時点で、pm-test1 の接続が切れます。
pm-test2 で、Pacemakerの状態を確認します。
(pm-test2)
# pcs status
Cluster name: cluster01
Status of pacemakerd: 'Pacemaker is running' (last updated 2023-04-19 12:07:38 +09:00)
Cluster Summary:
* Stack: corosync
* Current DC: pm-test2 (version 2.1.4-5.el8_7.2-dc6eb4362e) - partition with quorum
* Last updated: Wed Apr 19 12:07:39 2023
* Last change: Wed Apr 19 12:02:29 2023 by hacluster via crmd on pm-test1
* 2 nodes configured
* 4 resource instances configured
Node List:
* Online: [ pm-test2 ]
* OFFLINE: [ pm-test1 ]
Full List of Resources:
* Resource Group: rg01:
* rs-vip (ocf::heartbeat:IPaddr2): Started pm-test2
* rs-systemd-nginx (systemd:nginx): Started pm-test2
* Clone Set: rs-ping-gw-clone [rs-ping-gw]:
* Started: [ pm-test2 ]
* Stopped: [ pm-test1 ]
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
pcsd: active/enabled
↑Virtual IPとNginxが、pm-test2 に切り替わったことがわかります。
pm-test2 のログ /var/log/messages で、時系列で何が起こったかを確認してみます。
# less /var/log/messages Apr 19 12:07:33 pm-test2 corosync[966]: [KNET ] link: host: 1 link: 0 is down Apr 19 12:07:33 pm-test2 corosync[966]: [KNET ] host: host: 1 (passive) best link: 0 (pri: 1) Apr 19 12:07:33 pm-test2 corosync[966]: [KNET ] host: host: 1 has no active links Apr 19 12:07:33 pm-test2 corosync[966]: [TOTEM ] Token has not been received in 2250 ms Apr 19 12:07:34 pm-test2 corosync[966]: [TOTEM ] A processor failed, forming new configuration: token timed out (3000ms), waiting 3600ms for consensus. Apr 19 12:07:38 pm-test2 corosync[966]: [QUORUM] Sync members[1]: 2 Apr 19 12:07:38 pm-test2 corosync[966]: [QUORUM] Sync left[1]: 1 Apr 19 12:07:38 pm-test2 corosync[966]: [TOTEM ] A new membership (2.36) was formed. Members left: 1 Apr 19 12:07:38 pm-test2 corosync[966]: [TOTEM ] Failed to receive the leave message. failed: 1 Apr 19 12:07:38 pm-test2 corosync[966]: [QUORUM] Members[1]: 2 Apr 19 12:07:38 pm-test2 corosync[966]: [MAIN ] Completed service synchronization, ready to provide service. Apr 19 12:07:38 pm-test2 pacemaker-fenced[1077]: notice: Node pm-test1 state is now lost Apr 19 12:07:38 pm-test2 pacemaker-fenced[1077]: notice: Purged 1 peer with id=1 and/or uname=pm-test1 from the membership cache Apr 19 12:07:38 pm-test2 pacemaker-based[1076]: notice: Node pm-test1 state is now lost Apr 19 12:07:38 pm-test2 pacemaker-based[1076]: notice: Purged 1 peer with id=1 and/or uname=pm-test1 from the membership cache Apr 19 12:07:38 pm-test2 pacemaker-controld[1081]: notice: Node pm-test1 state is now lost Apr 19 12:07:38 pm-test2 pacemaker-controld[1081]: warning: Our DC node (pm-test1) left the cluster Apr 19 12:07:38 pm-test2 pacemaker-controld[1081]: notice: State transition S_NOT_DC -> S_ELECTION Apr 19 12:07:38 pm-test2 pacemaker-attrd[1079]: notice: Node pm-test1 state is now lost Apr 19 12:07:38 pm-test2 pacemaker-attrd[1079]: notice: Removing all pm-test1 attributes for peer loss Apr 19 12:07:38 pm-test2 pacemaker-attrd[1079]: notice: Purged 1 peer with id=1 and/or uname=pm-test1 from the membership cache Apr 19 12:07:38 pm-test2 pacemaker-controld[1081]: notice: State transition S_ELECTION -> S_INTEGRATION Apr 19 12:07:38 pm-test2 pacemaker-controld[1081]: notice: Cluster does not have watchdog fencing device Apr 19 12:07:38 pm-test2 pacemaker-schedulerd[1080]: notice: On loss of quorum: Ignore Apr 19 12:07:38 pm-test2 pacemaker-schedulerd[1080]: warning: Blind faith: not fencing unseen nodes Apr 19 12:07:38 pm-test2 pacemaker-schedulerd[1080]: notice: Actions: Start rs-vip ( pm-test2 ) Apr 19 12:07:38 pm-test2 pacemaker-schedulerd[1080]: notice: Actions: Start rs-systemd-nginx ( pm-test2 ) Apr 19 12:07:38 pm-test2 pacemaker-schedulerd[1080]: notice: Calculated transition 0, saving inputs in /var/lib/pacemaker/pengine/pe-input-28.bz2 Apr 19 12:07:38 pm-test2 pacemaker-controld[1081]: notice: Initiating start operation rs-vip_start_0 locally on pm-test2 Apr 19 12:07:38 pm-test2 pacemaker-controld[1081]: notice: Requesting local execution of start operation for rs-vip on pm-test2 Apr 19 12:07:38 pm-test2 IPaddr2(rs-vip)[5372]: INFO: Adding inet address 192.168.1.178/24 with broadcast address 192.168.1.255 to device eth0 Apr 19 12:07:38 pm-test2 IPaddr2(rs-vip)[5372]: INFO: Bringing device eth0 up Apr 19 12:07:38 pm-test2 IPaddr2(rs-vip)[5372]: INFO: /usr/libexec/heartbeat/send_arp -i 200 -r 5 -p /run/resource-agents/send_arp-192.168.1.178 eth0 192.168.1.178 auto not_used not_used Apr 19 12:07:38 pm-test2 pacemaker-controld[1081]: notice: Result of start operation for rs-vip on pm-test2: ok Apr 19 12:07:38 pm-test2 pacemaker-controld[1081]: notice: Initiating monitor operation rs-vip_monitor_10000 locally on pm-test2 Apr 19 12:07:38 pm-test2 pacemaker-controld[1081]: notice: Requesting local execution of monitor operation for rs-vip on pm-test2 Apr 19 12:07:38 pm-test2 pacemaker-controld[1081]: notice: Initiating start operation rs-systemd-nginx_start_0 locally on pm-test2 Apr 19 12:07:38 pm-test2 pacemaker-controld[1081]: notice: Requesting local execution of start operation for rs-systemd-nginx on pm-test2 Apr 19 12:07:38 pm-test2 systemd[1]: Reloading. Apr 19 12:07:38 pm-test2 pacemaker-controld[1081]: notice: Result of monitor operation for rs-vip on pm-test2: ok Apr 19 12:07:38 pm-test2 systemd[1]: /usr/lib/systemd/system/irqbalance.service:6: Unknown lvalue 'ConditionCPUs' in section 'Unit' Apr 19 12:07:38 pm-test2 systemd[1]: Starting Cluster Controlled nginx... Apr 19 12:07:38 pm-test2 nginx[5520]: nginx: the configuration file /etc/nginx/nginx.conf syntax is ok Apr 19 12:07:38 pm-test2 nginx[5520]: nginx: configuration file /etc/nginx/nginx.conf test is successful Apr 19 12:07:38 pm-test2 systemd[1]: nginx.service: Failed to parse PID from file /run/nginx.pid: Invalid argument Apr 19 12:07:38 pm-test2 systemd[1]: Started Cluster Controlled nginx. Apr 19 12:07:40 pm-test2 pacemaker-controld[1081]: notice: Result of start operation for rs-systemd-nginx on pm-test2: ok Apr 19 12:07:40 pm-test2 pacemaker-controld[1081]: notice: Initiating monitor operation rs-systemd-nginx_monitor_60000 locally on pm-test2 Apr 19 12:07:40 pm-test2 pacemaker-controld[1081]: notice: Requesting local execution of monitor operation for rs-systemd-nginx on pm-test2 Apr 19 12:07:40 pm-test2 pacemaker-controld[1081]: notice: Result of monitor operation for rs-systemd-nginx on pm-test2: ok Apr 19 12:07:40 pm-test2 pacemaker-controld[1081]: notice: Transition 0 (Complete=6, Pending=0, Fired=0, Skipped=0, Incomplete=0, Source=/var/lib/pacemaker/pengine/pe-input-28.bz2): Complete Apr 19 12:07:40 pm-test2 pacemaker-controld[1081]: notice: State transition S_TRANSITION_ENGINE -> S_IDLE Apr 19 12:07:42 pm-test2 IPaddr2(rs-vip)[5372]: INFO: ARPING 192.168.1.178 from 192.168.1.178 eth0#012Sent 5 probes (5 broadcast(s))#012Received 0 response(s)
↑12:07:40 までには、pm-test2 でVirtual IPが割り当てられ、Nginxが起動したことがわかります。
12:07:31 にネットワークを切断したので、10秒程度でフェイルオーバーが完了しました。
Virtual IP で、Webページにアクセスしてみます。
# curl http://192.168.1.178/test.html <!DOCTYPE html> <html> <head> <meta charset="UTF-8" /> <title>Test Page</title> </head> <body> <h1>Test Page</h1> test page on pm-test2. </body> </html>
↑pm-test2 にアクセスしています。
想定どおりの自動フェイルオーバーを確認できました。
想定する障害C. サーバーOSダウン
(想定する動作)
- Pacemakerは自動フェイルオーバーする。
- 数秒程度で切り替わる。
実際に試してみます。
まず、Pacemakerの状態を確認します。
# pcs status
Cluster name: cluster01
Status of pacemakerd: 'Pacemaker is running' (last updated 2023-04-19 18:48:46 +09:00)
Cluster Summary:
* Stack: corosync
* Current DC: pm-test1 (version 2.1.4-5.el8_7.2-dc6eb4362e) - partition with quorum
* Last updated: Wed Apr 19 18:48:47 2023
* Last change: Wed Apr 19 18:04:36 2023 by root via cibadmin on pm-test2
* 2 nodes configured
* 4 resource instances configured
Node List:
* Online: [ pm-test1 pm-test2 ]
Full List of Resources:
* Resource Group: rg01:
* rs-vip (ocf::heartbeat:IPaddr2): Started pm-test1
* rs-systemd-nginx (systemd:nginx): Started pm-test1
* Clone Set: rs-ping-gw-clone [rs-ping-gw]:
* Started: [ pm-test1 pm-test2 ]
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
pcsd: active/enabled
↑Virtual IPとNginxリソースが、pm-test1 でアクティブとなっています。
pm-test1 のOSをシャットダウンします。
(pm-test1)
# date; shutdown -h now Wed Apr 19 18:49:41 JST 2023
pm-test1 にSSH接続していれば、この時点で、pm-test1 の接続が切れます。
pm-test2 で、Pacemakerの状態を確認します。
(pm-test2)
# pcs status
Cluster name: cluster01
Status of pacemakerd: 'Pacemaker is running' (last updated 2023-04-19 18:49:54 +09:00)
Cluster Summary:
* Stack: corosync
* Current DC: pm-test2 (version 2.1.4-5.el8_7.2-dc6eb4362e) - partition with quorum
* Last updated: Wed Apr 19 18:49:54 2023
* Last change: Wed Apr 19 18:04:36 2023 by root via cibadmin on pm-test2
* 2 nodes configured
* 4 resource instances configured
Node List:
* Online: [ pm-test2 ]
* OFFLINE: [ pm-test1 ]
Full List of Resources:
* Resource Group: rg01:
* rs-vip (ocf::heartbeat:IPaddr2): Started pm-test2
* rs-systemd-nginx (systemd:nginx): Started pm-test2
* Clone Set: rs-ping-gw-clone [rs-ping-gw]:
* Started: [ pm-test2 ]
* Stopped: [ pm-test1 ]
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
pcsd: active/enabled
↑Virtual IPとNginxが、pm-test2 に切り替わったことがわかります。
pm-test2 のログ /var/log/messages を確認してみます。
# less /var/log/messages Apr 19 18:49:44 pm-test2 systemd[1]: Started Cluster Controlled nginx. ... Apr 19 18:49:48 pm-test2 IPaddr2(rs-vip)[13491]: INFO: ARPING 192.168.1.178 from 192.168.1.178 eth0#012Sent 5 probes (5 broadcast(s))#012Received 0 response(s)
↑18:49:48 までには、pm-test2 でVirtual IPが割り当てられ、Nginxが起動したことがわかります。
18:49:41 にネットワークを切断したので、7秒程度でフェイルオーバーが完了しました。
Virtual IP で、Webページにアクセスしてみます。
# curl http://192.168.1.178/test.html <!DOCTYPE html> <html> <head> <meta charset="UTF-8" /> <title>Test Page</title> </head> <body> <h1>Test Page</h1> test page on pm-test2. </body> </html>
↑pm-test2 にアクセスしています。
想定どおりの自動フェイルオーバーを確認できました。
想定する障害D. Pacemakerの不具合発生
(判断は難しいが、Pacemakerの動作がおかしいと判断したら)手作業で対応する。
具体的には、、
いったん2台ともpacemakerサービスを停止する。
各種関連ログを調査し、問題ないようなら、1台ずつPacemakerサービスを起動し、pcs resource cleanup コマンドでエラー状態をクリアする。
それでも解消されない場合は、Pacemakerの設定をいったんクリアして再設定する。
Pacemakerの再設定は、
pcs cluster stop コマンドでクラスターを停止、
pcs cluster destroy コマンドでクラスターの全設定を削除したのち、
一からPacemakerを設定します。
(pm-test1, pm-test2)
# pcs cluster stop # pcs cluster destroy
※ノード間でpcsの通信ができていないかもしれないので、pcs cluster stop, pcs cluster destroy コマンドは、全ノードで実行します。
7. おわりに
負荷分散用途のNginxサーバーをPacemakerで冗長化する構築手順と、Packmakerの動作、自動/手動フェイルオーバーなどについて記載しました。
長くなりましたが、今回のような構成、仕様であれば、構築手順や操作は、シンプルでわかりやすいと思います。
AWSなどのパブリッククラウドでは、内部的に冗長化されているELBなどのロードバランサー機能を使用すべきですが、そのような機能がないオンプレミスなどの環境では有用でしょう。
実際に導入する際は、想定する障害に対して、十分な動作確認の実施をおすすめします。
(参考記事)
(1) NGINXの負荷分散装置をPacemakerで冗長化する – 技術メモメモ
https://tech-mmmm.blogspot.com/2022/06/nginxpacemaker.html
(2) CentOS 8 + PacemakerでSquidとUnboundを冗長化する – 技術メモメモ
https://tech-mmmm.blogspot.com/2020/07/centos-8-pacemakersquidunbound.html
(3) 技術メモメモ ラベル:Pacemaker – 技術メモメモ
https://tech-mmmm.blogspot.com/search/label/Pacemaker
(4) 高可用性クラスタリングの設定 Oracle Linux Help Center
https://docs.oracle.com/cd/F22978_01/availability/availability-InstallingandConfiguringPacemakerandCorosync.html
(5) 高可用性クラスターの設定および管理 – A Red Hat training course is available for RHEL 8
https://access.redhat.com/documentation/ja-jp/red_hat_enterprise_linux/8/html/configuring_and_managing_high_availability_clusters/index
(6) 【Pacemaker】HAクラスタの運用で注意すべき「スプリットブレイン」とは? – ラクスエンジニアブログ
https://tech-blog.rakus.co.jp/entry/20220302/pacemaker
(7) pcs Man Page – ManKier
https://www.mankier.com/8/pcs
(8) Pacemakerの概要 – Linux-HA Japan
https://linux-ha.osdn.jp/wp/manual/pacemaker_outline
(9) Pacemaker/Corosync の設定値について – SRA OSS Tech Blog
https://www.sraoss.co.jp/tech-blog/pacemaker/pacemaker-config-values/
(10) Pacemaker Explained 4. Cluster Resources
https://clusterlabs.org/pacemaker/doc/2.1/Pacemaker_Explained/html/resources.html
(11) クラスタ構成ソフトウェア「Pacemaker」と「Heartbeat」「Corosync」の関係性 – ビジネス継続とITについて考える
https://bcblog.sios.jp/drbd-pacemaker-heartbeat-corosync/