先日、LinuxサーバーにHTMLリンクチェックツールを導入する機会がありました。
webcheckというツールが使いやすかったのでここで紹介します。
HTMLリンクチェックツール
調べてみたところ、このジャンルのツールは、WebサービスやPC上で動作するクライアントアプリはあるものの、Linux上で動作するものはほとんどなく、使えそうなのは次の3つでした。
この3つを実際に試したところ、
- リンクチェックを動作させるサーバーへの負荷が少ない。
- レポートがしっかりしている。
という利点のある、webcheckを採用しました。
webcheckのインストール手順や使い方は、以下の記事を参考にしました。
ありがとうございます。
(参考)
・VineLinuxパフォーマンスアッププロジェクト:0197
リンク切れを総チェックするには
http://mkserver.dip.jp/vinelinux/perform/apache/0197.html
webcheckについて
webcheckはPython製のツールです。
HTMLリンクチェックのほか、サイトマップ、外部サイトのリスト等の機能もあります。
Webクローラーと同じようなしくみでHTTPクライアントとして動作し、
- Webページのダウンロード
- HTMLの解析
- リンクをたどって他のWebページのダウンロード
を繰り返し、HTML形式のレポートを出力します。
webcheckのインストール先サーバーとしては、HTTPクライアントですから、
- チェック対象のWebサイトを載せているWebサーバー
- 監視専用等の別サーバー
のどちらでもよいでしょう。
後者のように別サーバーにインストールすると、チェックツールプロセスによるサーバー負荷を軽減することができます。
また、複数のWebサイトに対して順にチェックを実行してレポートを作成する、ということも可能となります。
webcheckのインストール
以下、CentOS 6,7にインストールする場合の手順です。
Python 2.6, 2.7のどちらでも動作します。
ここでは、インストール先を /usr/local/webcheck とします。
オフィシャルサイトからダウンロード、展開します。
# cd /usr/local/src/ # wget https://arthurdejong.org/webcheck/webcheck-1.10.4.tar.gz # tar zxvf webcheck-1.10.4.tar.gz # mv webcheck-1.10.4 /usr/local/webcheck
webcheck.py が、webcheckの実行プログラムです。
# ls -l /usr/local/webcheck/webcheck.py -- -rwxr-xr-x 1 root root 10761 Jan 4 2010 webcheck.py --
また、PythonのHTMLパーサーライブラリが必要となるため、EPELリポジトリよりpython-beatifulsoup4パッケージをインストールします。
# yum --enablerepo=epel install python-beautifulsoup4
webcheckのレポート出力先とレポートページの表示設定
ここでは、
- レポート出力先: /var/www/webcheck
- レポートページのURL: http://<servername>/webcheck/
とします。
レポート出力先を作成します。
# mkdir /var/www/webcheck
WebサーバーのConfigにレポートページ表示設定を追記して、サービスをreloadもしくはrestartします。
-- Apacheの場合
Alias /webcheck /var/www/webcheck
--
-- Nginxの場合
location /webcheck {
alias /var/www/webcheck;
}
--
※実際には、BASIC認証やアクセス元IPアドレスによる制限をかけたほうがよいでしょう。
webcheckの実行
webcheckの実行コマンドは次のとおりです。
-f オプションで、レポートデータを上書きします。
# /usr/local/webcheck/webcheck.py \ -f -o <レポート出力先> <チェック対象WebサイトURL>
以下、Webサイト「稲葉サーバーデザイン」をチェックし、レポートを /var/www/webcheck に出力する場合。
# /usr/local/webcheck/webcheck.py \ -f -o /var/www/webcheck https://inaba-serverdesign.jp/
※このとき、PythonのHTMLパーサーライブラリが存在しないと、以下のようなメッセージを出力して、終了します。
webcheck: Warning: falling back to the legacy HTML parser, consider installing BeautifulSoup webcheck: Warning: tidy library (python-utidylib) is unavailable
今回はWebサイトと同じサーバーにインストール、実行しました。
サーバーのスペックは0.8GHz x 1vCPU, メモリ1GBで、Webサイトのページ数は224。
実行時間は22分22秒で、この間のサーバー負荷は次のとおりです。
- CPU Load Average: 最大0.8
- CPU使用率: 最大80%
- webcheckプロセスのメモリ使用量: 50MB
Webサイトと同じサーバーでwebcheckを実行しているので、webchekのプロセスと、webcheckによるHTTPアクセスを処理するWebサーバー(Nginx)プロセスの両方による負荷がかかっています。
Webサイトのページ数がそれほど多くないのに時間がかかっているのは、外部リンクが761と内部ページより多いからでしょうか。
ただ、実行が速いと、逆にWebサーバーに負荷をかけてしまうので、これぐらいの速度がちょうどよいのかもしれません。
webcheckをWebサイトと同居するにせよしないにせよ、Webサーバーへの負荷はかかるので、深夜早朝等、アクセスが少ない時間帯に自動実行するようcronで設定するのがよいでしょう。
以下は、毎週日曜日の6時30分に実行する設定例です。
# crontab -e -- # HTML Link Check 30 6 * * 0 /usr/local/webcheck/webcheck.py -f -o <レポート出力先> <チェック対象WebサイトURL> > /var/log/webcheck.log --
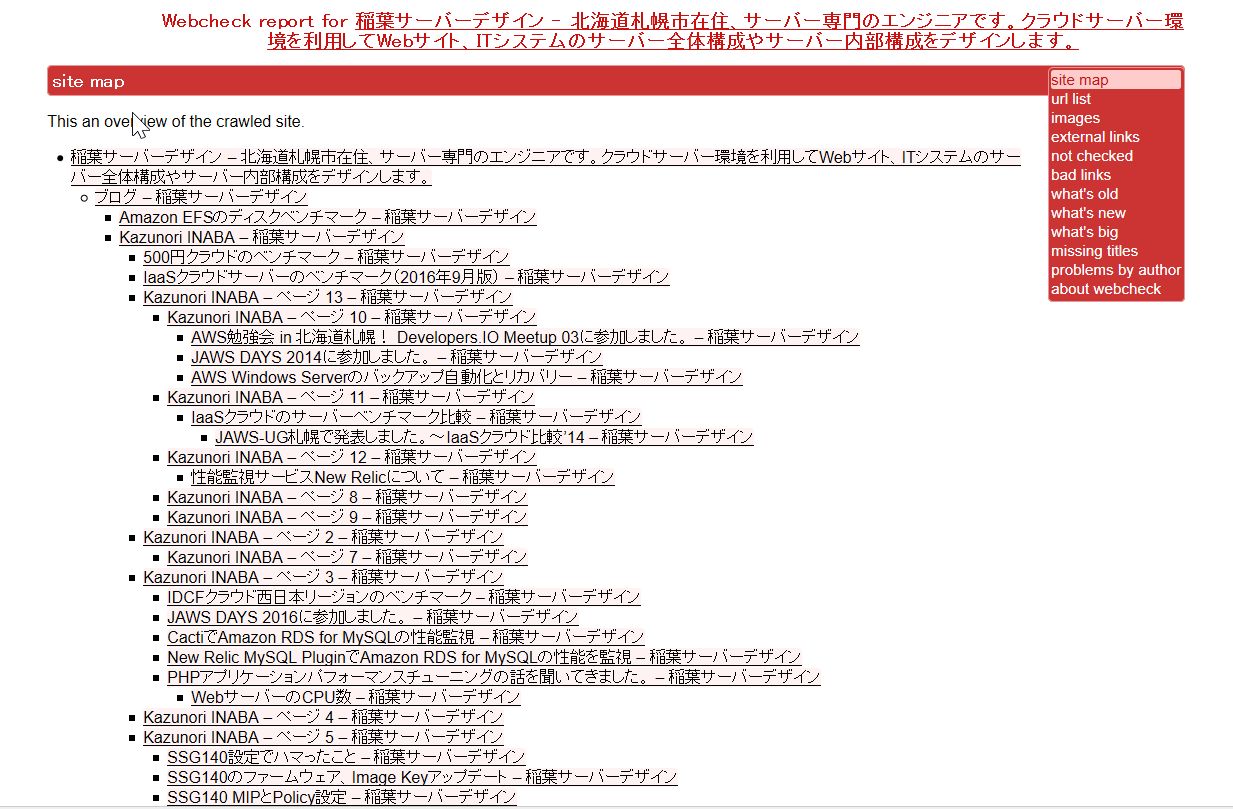
webcheckのレポートページ
Webブラウザからレポートページ(http://<servername>/webcheck/)にアクセスしてみます。
レポートページはこんな感じです。
レポートのトップページでは、サイトマップを表示します。
「bad links」ページで、リンク切れページをリスト表示します。

HTMLの記述ミスによるのリンク切れを3つ発見でき、記事を修正しました。
あとは外部サイトの「301: Moved Permanently」や「404: Not Found」がけっこうたくさんありました。
ブログ記事の中で参考記事として紹介している外部サイトのページが、いつの間にか移動したり、なくなったりしたものですね。
よい記事が参照できなくなってしまうのは残念です。
まとめ
WebサイトのHTMLリンクをチェックするwebcheckというツールの、インストール方法や使い方、サーバーの負荷についてまとめました。
オフィシャルサイトからダウンロードできるバージョンは2010年9月にリリースされたもので少し古いのですが、インストールが比較的簡単で、動作は軽量、シンプルながらわかりやすいレポートページを生成してくれるので、よいツールだと思います。
Webサイトのページ数が増えると、リンクの不整合が発生するケースもあるかと思いますので、こういったツールで定期的にチェックするとよいでしょう。